3. How it works
3.1 Overview
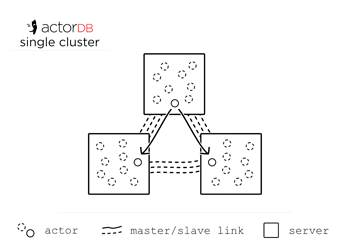
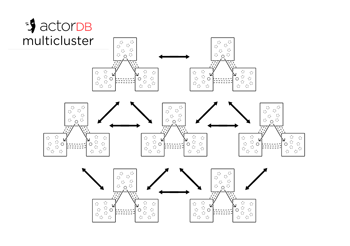
ActorDB is organised into clusters (1,3,5 nodes). There can be as many clusters as you wish. Actors themselves are organised into shards. Logically a shard is a chunk of hash namespace. It is a special type of actor that holds a list of regular actors. Shards live within clusters and so do their actors.
An actor is a mini fully relational SQL database. It has a leader node that processes reads and writes, it has follower nodes on other servers in the cluster that receive writes from leader. Writes are replicated using the Raft distributed consensus protocol. If a server is offline, one of the followers will automatically become a leader for that actor. As long as a majority of servers in a cluster are online, writes will succeed.
A single actor is not scalable, it is fast enough. A single actor can do thousands of writes per second and tens of thousands of reads. The database as a whole is completely horizontally scalable, because actors are independent of each other.
3.2 Node synchronisation
3.2.1 Global state
ActorDB is designed around having to do the least possible inter-server synchronisation. That means each server should be as independent as possible and global state and the changing of that global state should be minimised.
Everything in ActorDB is an actor. This includes global state. It is a special actor that lives on up to 7 nodes (over multiple clusters). Those 7 nodes maintain strong consistency using Raft distributed consensus. If ActorDB has more than 7 nodes, the rest get their state by periodic pings from current leader node.
Global state for ActorDB:
- 1. List of nodes (changed manually by user).
- 2. Database schema (changed manually by user).
- 3. List of shards and which node owns which shard (caused by change in list of nodes).
- 4. uniqid current max value (set automatically).
- 5. List of nodes that are part of the global state group.
3.2.2 Actors
All ActorDB requests are always sent to an actor. Steps from receiving request sending request to actor:
- 1. Calculate a hash of actor name.
- 2. Check the hash table of shards to find which node that actor lives in.
- 3. Send request to what should be leader node.
- 4. If what should be leader node is actually not, request will be redirected to the actual leader.
ActorDB has two distinct engines: SQLite for running SQL queries and LMDB for storage. The SQL engine uses pages to store data (chunks of 4096 bytes). Those pages are not stored to SQLite files, they are stored inside LMDB. We replaced the SQLite WAL implementation with our own, which is actually faster on an individual actor basis then just using SQLite. Unlike regular WAL mode we do not need to checkpoint pages somewhere else later on. Once a page is stored, it is kept where it is. It is also compressed using lz4.
Unlike most other databases (especially SQL databases), ActorDB does not require checkpoints from WAL to the main database file. Using LMDB we are able to store pages in an append-only style. This way checkpoints are replaced with cleanups that only free up space for later use.
Actors are replicated using the Raft distributed consensus protocol. Raft requires a write log to operate. Because our two engines are connected through the SQLite WAL module, Raft replication is a natural fit. Every write to the database is an append to WAL. For every append we send that data to the entire cluster to be replicated. Pages are simply inserted to WAL on all nodes. This means the leader executes the SQL, but the followers just append to WAL.
If a server is very stale or is added new, ActorDB will first send the base actor pages to the new server, then it will send the WAL pages (if there are any).
You can configure the server to use multiple independent hard drives and ActorDB will balance actors across all of them. This will significantly improve throughput as long as cpu and network are not saturated.
3.2.3 Multi-actor transactions
Multi-actor transactions need to be ACID compliant. They are executed by a transaction manager. The manager is itself an actor. It has name and a transaction number that is incremented for every transaction.
Sequence of events from the transaction manager point of view:
- 1. Start transaction by writing the number and state (uncommitted) to transaction table of transaction manager actor.
- 2. Go through all actors in the transaction and execute their belonging SQL to check if it can execute, but do not commit it. If actor successfully executes SQL it will lock itself (queue all reads and writes).
- 3. All actors returned success. Change state in transaction table for transaction to committed.
- 4. Inform all actors that they should commit.
Sequence of events from an actors point of view:
- 1. Actor receives SQL with a transaction ID, transaction number and which node transaction manager belongs to.
- 2. Store the actual SQL statement with transaction info to a transaction table (not execute it).
- 3. Once it is stored, the SQL will be executed but not committed. If there was no error, return success.
- 4. Actor waits for confirm or abort from transaction manager. It will also periodically check back with the transaction manager in case the node where it was running from went down and confirmation message is lost.
- 5. Once it has a confirmation or abort message it executes it and unlocks itself.
Problem scenarios:
- 1. Node where transaction manager lives goes down before committing transaction: Actors will be checking back to see what state a transaction is in. If transaction manager actor resumes on another node and sees an uncommitted transaction, it will mark it as aborted. Actors will in turn abort the transaction as well.
- 2. Node where transaction manager lives goes down after committing transaction to local state, but before informing actors that transaction was confirmed. Actors checking back will detect a confirmed transaction and commit it.
- 3. Node where one or more actors live goes down after confirming that they can execute transaction. The actual SQL statements are stored in their databases. The next time actors start up, they will notice that transaction. Check back with the transaction manager and either commit or abort it.
3.3 SQL engine
ActorDB does not reinvent the SQL engine. It relies on one of the most well tested and stable pieces of code in use: SQLite
Remember that SQLite is not itself a separate program. It is a software library which is a part of ActorDB. Running many or just one actor on a server does not make a difference. There is no global SQLite lock that blocks one actor from doing work because another is using it.
ActorDB can easily handle thousands of requests per second for a single actor. For our purposes SQLite is an ideal engine.
SQLite provides a list of cases where its use is not recommended. None of them apply to ActorDB (https://www.sqlite.org/whentouse.html).
Client/Server Applications - ActorDB takes care of the network protocol. It is very suitable for a client/server application over the network.
High-volume Websites - ActorDB is able to spread the load across as many servers and SQLite instances as you throw at it. It will thus be very suitable for high-volume websites.
Very large datasets - As long as you do not have a very large dataset inside a single actor (many GB) and spread the data across many actors, ActorDB will work very well even with petabytes of data.
High Concurrency - ActorDB is massively concurrent. Not on the individual actor level, but across the entire database.